【特別コラム連載】会計ファイナンス人材×AI第8回 ビジネスでのAI利用の注意点 前編

目次
ハルシネーションについて
外山:みなさん、こんにちは。
今回は、実務でAIを利用する上で注意すべき点について解説したいと思います。AIは比較的新しい技術にも関わらず、急速に業務にも浸透しつつあります。そのため、リスクを理解した上で使うことが大事だと思います。
鈴木:よろしくお願いします。AIのリスクといえば、私がまず思い浮かぶのはハルシネーションですね。最近のAIは非常に質の高い回答をしてくれるのですが、誤った内容が含まれていることがあり、完全に信用するのは危険だと思っています。
外山:ChatGPTのような大規模言語モデルによる、事実に基づかない回答を、ハルシネーションと呼びますね。特に初期バージョンのChatGPT(GPT-3.5)はハルシネーションが多かったため、「AIは信用できない」という声につながりました。最近のAIは性能も高まり、Web検索もできるため、ハルシネーションはかなり減ったと思いますが、それでもゼロにすることは原理的に不可能だと言われています。
鈴木:AIの性能が高まっていけば、いつかは無くなるのかと思っていました。
外山:では、ハルシネーションの問題について、機械学習の基本に立ち返って考えてみましょう。最も単純な、最小二乗法を用いて一次方程式を導く例からスタートします。このような機械学習手法を、線形回帰と呼びましたね。
取得したxとyの情報を、グラフ上に濃い青でプロット(点を配置すること)して、最小二乗法によって導かれた式を、緑の直線で描画します。下記の例では、y = x + 10 という式が描かれました。この式を導く流れを、ざっくりと説明してください。
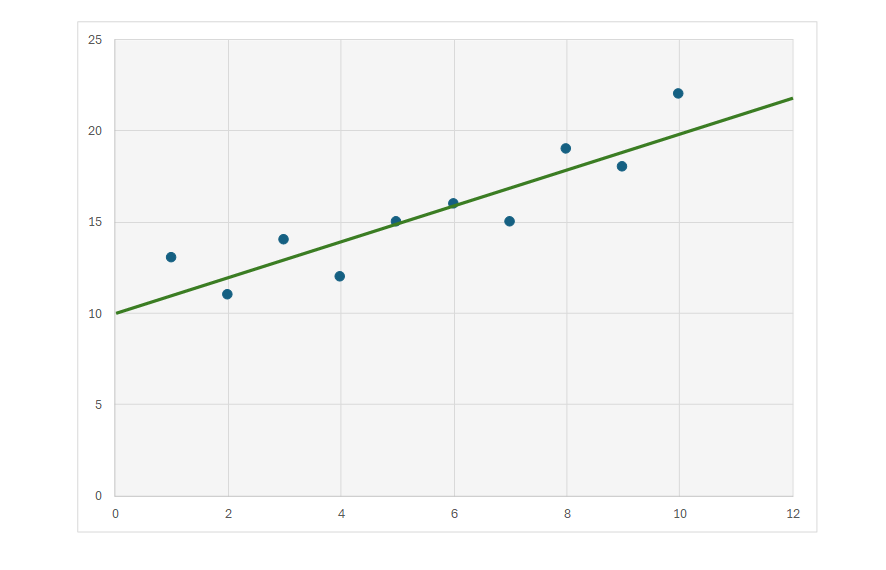
鈴木:まず、y = ax + b という一次方程式を仮定し、この式が表す直線と、各データ(点)との距離を求めます。具体的には、各点から線に対して垂直に下ろした線(薄い青の線)の長さを計算し、続いて、それらの線の長さを2乗したものの合計値が、最も小さくなるようなaとbを求めるのでした。
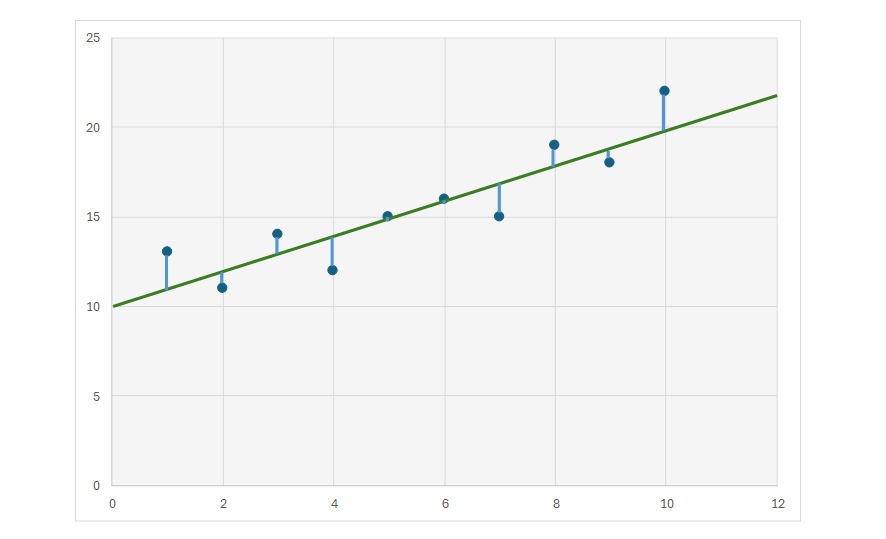
外山:そうですね。言い換えれば、全ての座標との誤差が最も小さい直線を求めたということになります。では、最小二乗法によって導き出されたこの数式は、絶対に正しいと言えますか?
鈴木:計算過程には誤りはないと思いますが、絶対と言われると…。例えばですが、計算の元になるデータに測定ミスがあった場合は、正確な式にはなりませんね。
外山:そのような問題もありますが、全てのデータが正しく取得できている場合はどうでしょう。
機械学習とは、データのパターンや特徴を学習し、それによって未知のデータに対しても予測をすることができるという技術だったことを思い出してください。
鈴木:予測がキーワードでしたね。例えば、xが12の場合、先ほどの式を用いることで、yは22だろうと予測できます。この数式が絶対に正しいと言えるためには、xが12のときは、確実にyは22だと断言できる必要がありますね…。しかし、そのような断言はできないと思います。
外山:厳密な自然科学的法則に当てはめるならまだしも、例えば、ネコの体長(x)と、ネコのしっぽの長さ(y)の場合などは、絶対に正しいと言える予測はできませんよね。何千何万というネコのデータを学習させても、体長30センチのネコのしっぽの長さを正確に予測できるモデル(機械学習によって導かれた数式)を作ることは不可能です。
機械学習ができるのは、あくまで統計学的に最も確率が高い値を導くことだけです。先ほどの数式で言えば、「取得したデータによると、xが12のときは、yは22である確率が最も高い」という以上のことは分からないのです。
鈴木:学習したデータに依存しているという点も大事ですよね。先ほどの例も、たまたま取得した10個のデータから導かれた式にすぎないわけで、もっと大量のデータを集めてきたら、式の傾きや切片(パラメーター)が変わってしまうということも、当然あると思います。
外山:そうですね。データを増やせば、より実態を反映したモデルができるはずですが、それでも完璧ということはあり得ません。現実のデータは、明確な法則に従っているわけではありませんし、中には外れ値と呼ばれるような例外的な値を持ったデータもあります。完璧な予測はできないという割り切りも必要なのです。
文章生成の裏側
鈴木:分かってきました。生成AIも、文章を予測しているという点では同じですよね。つまり、完璧に「正しい」文章を予測することはできない以上、ハルシネーションは避けられないということですか。
外山:そういうことになります。特に具体的な事実関係などは、AIを完全に信用せず、信頼できるサイト等でチェックすることを推奨します。
では、ここで文章生成の具体的な仕組みについて、少し補足しておきましょう。第5回『生成AIとは何か』で軽く触れましたが、大規模言語モデルは、与えられた文章に続く確率が最も高い単語(正確には「トークン」という単位です)を予測しているのでした。
例えば、「日本で一番高い山は」という文章が与えられたとして、続く単語はどうなるでしょうか。十分な日本語文書を学習したAIでしたら、以下のようになるかもしれません(あくまで例であり、正確な予測ではありません)。
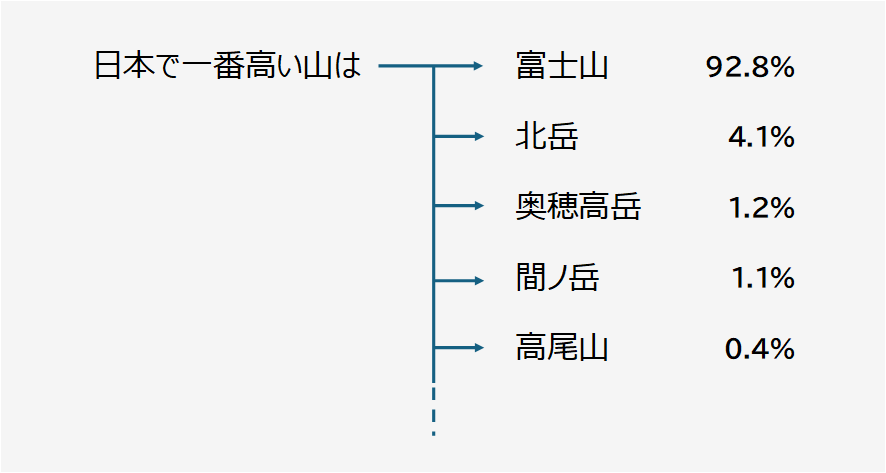
鈴木:普通に考えれば、「富士山」が続くと思われますね。この例でも、富士山が圧倒的に高い確率になっていて、それに続いて、標高が高い山や、有名な山が候補に挙がっているようです。
外山:第4回『機械学習とは何か』でもお見せした、ニューラルネットワークの構造の図をご覧ください。
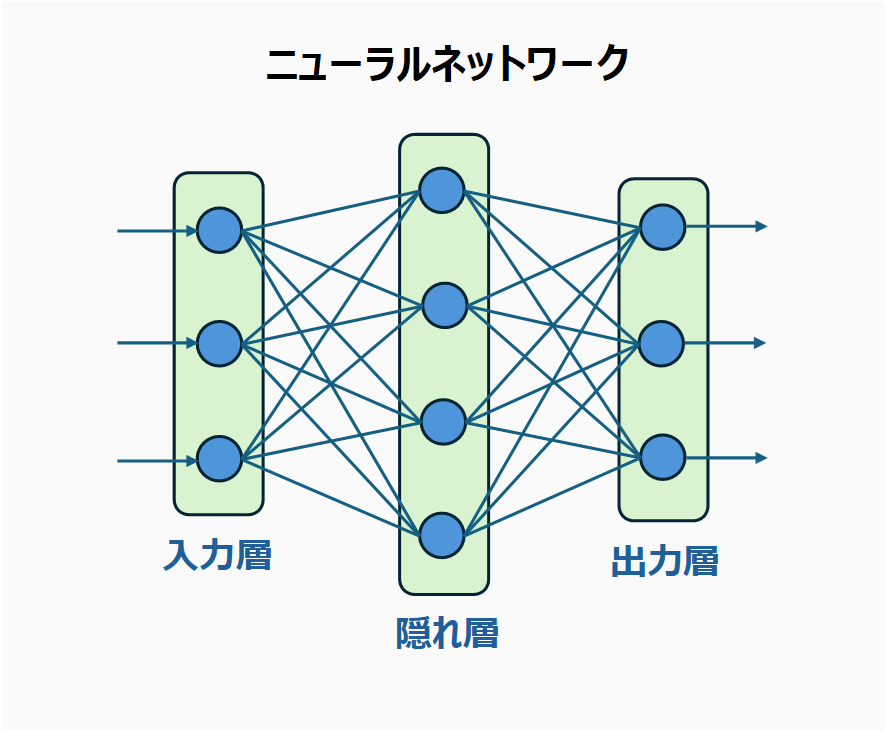
入力層からは、それまでの文章が入り、出力層からは、大量の単語の候補が、確率付きで出てくるというイメージです。もちろん、実際の大規模言語モデルはこれよりもずっと複雑な構造をしていますが、基本的な考え方は同じです。
元のデータに偏りがあったり、誤りが含まれていたり、学習プロセスで過学習(かがくしゅう)が発生したりすると、正確に実態を反映しない確率が出力され、ハルシネーションが発生してしまうというわけですね。
過学習とは
鈴木:過学習とは何でしょうか?
外山:やや専門的な機械学習用語ですが、ここで軽く説明しましょう。これについては、典型例を見ていただいた方が早いかもしれません。
先ほどの最小二乗法の例で言うと、より良い数式(モデル)とは、全ての座標との誤差が最も小さい数式であるはずでした。それは直線である必要はないため、二次方程式や三次方程式のようにパラメーターを増やしていけば、より柔軟で、複雑なデータにも対応できるモデルが作れそうな気がします。
そこで、先ほどの10個のデータに対して、パラメーター数の多い複雑な式を当てはめた場合に、以下のようになったとしましょう(オレンジの線)。このモデルは、先ほどの直線に比べ、データの傾向を正確に反映しているといえるでしょうか。
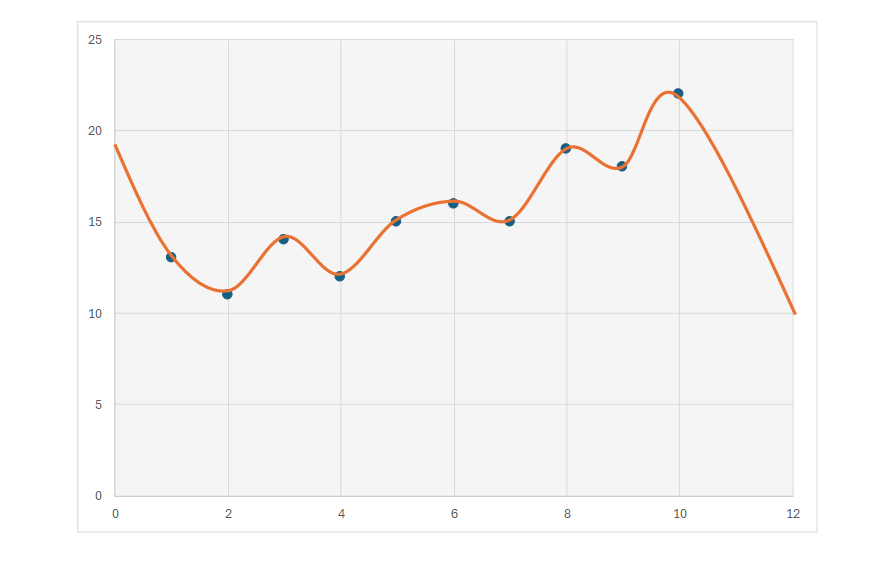
鈴木:これはデータの傾向を表しているとは言えませんね…。特に、0近辺や、10を超えたあたりは、全体の傾向から大きく外れています。
外山:このモデルは、与えられた全てのデータに完璧に適合できている(点と線の誤差ゼロ)にも関わらず、未知のデータへの予測性能は非常に低いです。
これはまさに過学習が発生している状態といえます。既知のデータに特化しすぎて、未知のデータに対する汎化に失敗した状態だと言うこともできます(過学習という語感から、「学習をさせすぎ」とか、「データを与えすぎ」という印象を受けるかもしれませんが、そのような意味はありません。最近では、過剰適合と呼ぶ場合も多いです)。
鈴木:機械学習の目的が、未知のデータでも正しく予測することだと考えれば、これは学習の失敗ということになりそうです。もし大規模言語モデルでしたら、ハルシネーションが発生する状態でしょうね。
外山:過学習によって起こるハルシネーションは、「偏見」がある状態と言えるかもしれません。わずかなデータだけを見て、それが完璧に実態を表していると信じてしまっているようなものです(例えば、たった10匹のネコを見て、そのネコが全て白かった場合に、「ネコは全て白いのだ」と思い込んでしまうような状態)。
AIに学習されるリスク
鈴木:生成AIのリスクというと、AIとの会話のために送信したデータが、学習に利用されてしまうというリスクもよく挙げられます。
外山:非常によく指摘されるリスクではありますが、それについては誤解もあるようです。まず押さえておくべきは、AIと会話したからといって、その会話内容が即時に学習されてしまうということは、原理的にあり得ないということです。
こういった最先端の論点であっても、よく分からないときは機械学習の基本に返ることが大事です。
先ほどの線形回帰のグラフを思い出してください。多数のデータを学習し、y = x + 10 という数式を導くことができましたよね。それにより、未知のxが現れた場合でも、それに対応するyの値を予測することが可能になったわけです。
鈴木:学習によって、予測できるようになったということですね。これが機械学習の本質でした。
外山:ここで重要なのは、学習のフェーズと、予測のフェーズは、明確に切り離されているということです。つまり、y = x + 10 という式を学習によって導いたあと、この式を用いて値を予測しても、予測に用いたデータが直ちに学習に利用されることはないということです。
鈴木:たしかに、y = x + 10という数式のxに12を代入して、それによってy が 22だと予測しても、y = x + 10 という式自体には何の影響もないですよね。何百回xに値を代入しても、式は変わりません。当然と言えば当然のことです。
外山:それは高度な生成AIであっても同じです。我々が業務で使うCopilotやGeminiのようなAIは、すでに学習が終わったものであって、それらと会話をすることは、予測のプロセスだと言えます。いくら予測をしても、それによってAIがその場で学習することはありません。機械学習の用語で言えば、予測によってパラメーターが更新されることはないということです。つまり、会話の内容を即座に覚えられてしまうこともあり得ません。
鈴木:ちょっと待ってください。私は業務でCopilotを使っていますが、それまでの会話の流れを踏まえた回答をしてくれます。過去の会話を覚えているように見えるのですが…
外山:それはよくある誤解なのです。これも具体例を使って解説しましょう。例えば、以下のような会話があるとします。
| ユーザー:今期の売上総利益率が少し下がっている原因は? AI:売上構成の変化や、製品別の原価上昇が影響している可能性があります。特に原価率の高い商品や案件の割合が増えていないか確認する必要があります。 ユーザー:詳細に分析したい。どの項目を見るべきでしょうか? AI:まず材料費、人件費、外注費に分解し、前年同期と比較すると要因を特定しやすいと思います。 |
このような場合、ユーザーとAIが、お互いのメッセージを交互に発信していると、鈴木さんは考えているわけですよね?
鈴木:はい、そうですね。違うのでしょうか?
外山:実は、以下のような流れで会話をしているのです。まずは、ユーザーからのメッセージが送られるのですが、ここは問題ありません。
| ユーザー:今期の売上総利益率が少し下がっている原因は? |
これに対し、AIからの返信が来ます。これも予想通りだと思います。
| AI:売上構成の変化や、製品別の原価上昇が影響している可能性があります。特に原価率の高い商品や案件の割合が増えていないか確認する必要があります。 |
問題はここからです。
次に、ユーザーから「詳細に分析したい。どの項目を見るべきでしょうか?」というメッセージが送られるわけですが、実は裏では以下3つの文章が送信されているのです。
| ユーザー:今期の売上総利益率が少し下がっている原因は? AI:売上構成の変化や、製品別の原価上昇が影響している可能性があります。特に原価率の高い商品や案件の割合が増えていないか確認する必要があります。 ユーザー:詳細に分析したい。どの項目を見るべきでしょうか? |
鈴木:最新のメッセージだけでなく、それまでの文章も全部送信しているということですか?
外山:そうです。AIは、自分が喋った直後に、それまでの会話の内容を全て忘れてしまう人のようなものです。ですので、毎回、過去の会話の流れを全て教えてあげる必要があるのです。
鈴木:AIは会話を覚えることができないにも関わらず、それまでの流れを踏まえた回答ができていた理由が分かりました。ユーザーが知らないところで、それまでの会話の流れが全て送られていたのですね…
ということは、会話が長くなると、非常に長いメッセージをAIに送信することになりますね。
外山:そうです。ただ、AIの記憶には限界があります。取り扱うことができる文字数(トークン数)の上限があるためです。これはコンテキスト長(Context LengthまたはContext Window)と呼ばれており、各AIモデルによって固有の長さが設定されていますが、一般には10万から100万文字弱くらいです。
鈴木:ということは、やりとりが長くなると、古いメッセージはAIの記憶から漏れてしまうということですか…。
AIと長くやりとりをしていると、過去のメッセージを忘れてしまうと感じることがありましたが、これはコンテキスト長が原因だったのですね。
外山:AIが扱うことができる文字数には上限があるということは覚えておきましょう。また、AIが一回一回の会話から直接学習することはないこということも理解していただけたと思います。
鈴木:では、AIにメッセージを送信しても、学習される危険性はないということでしょうか。
外山:今の話は、あくまでも会話内容が即時に学習される危険性はないということです。AIに対して送信されたデータが保存され、それが後にAIの学習に使われるということはあり得ます。
特に業務で使う場合は、送信データが学習に使われないかという点には注意すべきだと思います。エンタープライズ向けプランを選択するなどの対応は必須でしょうし、どのAIサービスを使うか、データの扱いをどうするのか、といった点を定めた、『AIガイドライン』を策定することも重要かと思います。
鈴木:私が勤めるパートナーズ綜合監査法人でも『生成AIの利用ガイドライン』を作成し、遵守を徹底しています。AIを正しく使用することは、対外的な信用にも繋がりますね。
外山:今回は比較的技術寄りのリスクを見ましたが、次回は著作権、スキル喪失などの他、最先端のAIが抱える問題などにも触れましょう。

外山 哲郎
有限責任パートナーズ綜合監査法人
金融系、ゲーム系、など幅広い分野でスマートフォンアプリやWebサイトの開発に携わる。 2017年からAI業務に従事。データ分析や、医療の分野でのAI活用の研究・開発などに携わる。 ライターとしても活動(ニコニコニュース(ニコニコ動画))。 2024年7月 有限責任パートナーズ綜合監査法人入所。 現在は、IT専門家として監査業務に携わる他、法人内のDXおよびAI活用を推進している。

鈴木 爽矢
有限責任パートナーズ綜合監査法人
2022年大学3年生時に公認会計士試験合格。 大学時代にはCPA会計学院で監査論のチューター及び広報部のマーケティング業務を行う。 その後大手監査法人、コンサルティング会社を経て現職の有限責任パートナーズ綜合監査法人に入所。 現在は主に、IPO準備会社や上場企業の会計監査に従事し、財務デューデリジェンスなどの非監査業務にも携わっている。