【特別コラム連載】会計ファイナンス人材×AI 第4回 機械学習とは何か

目次
AIの歴史の振り返り
外山:みなさん、こんにちは。今回は、前回に続いてAIの歴史を振り返りながら、機械学習の本質について学んでいきましょう。
鈴木:よろしくお願いします。機械学習という言葉に、難解な印象を抱いている人は多いと思います。
外山:たしかに奥は深いのですが、はじめから深く理解する必要はないので、楽しく学んでいけたらと思っています。機械学習について知ると、AIの理解が深まることは間違いありませんから。
鈴木:前回は、第2次AIブームまで扱いましたね。まだ機械学習は主役ではないようでした。
外山:そうですね。例えば、第2次AIブームでは、エキスパートシステムが注目を集めました。これは、AIに対して、人間が手作業で専門知識や推論方法などのルールを設定するというものだったのですが、あらゆるパターンを網羅的に設定することなどできないため、壁に突き当たったわけです。
そのような状況を打開するため、人間の介入に頼らず、AIが自らさまざまなパターンを学習してくれるような技術が求められたのです。
鈴木:そこで注目されたのが機械学習なのですね。
第1回の講義で習いましたが、機械学習というのは、与えられたデータをAIが学習し、そのデータのパターンや傾向、特徴などを発見するという技術でした。
機械学習としての最小二乗法
外山:機械学習の基盤は数学だと思ってください。大量の数値に対して、統計的・数学的な処理を行います。
抽象的な話ではイメージが湧きづらいと思いますが、最も単純な機械学習の手法として、「最小二乗法(最小自乗法)」があります。
鈴木:最小二乗法でしたら知っています、公認会計士試験のための勉強でも少し触れました。費用の固変分解を行う際に、操業度と総原価のパターンを把握し、固定費と変動費を推定すること等ができたと思います。
外山:簡単に復習しておきましょう。最小二乗法を用いて、最も単純な一次方程式に当てはめる例です。具体的には、あらかじめ用意された座標データから、以下のような一次方程式のパラメーター(aとb)を求めるのでした。
y = a x + b
鈴木:各座標と、 y = a x + b という数式との、距離(残差)の2乗の合計値を求めて、その合計値を最小にするaとbを求めるということですね。
外山:その通りです。イメージが湧きやすいよう、グラフを書いてみましょう。大量の座標データも用意したので、XY座標上にプロットしてみます。
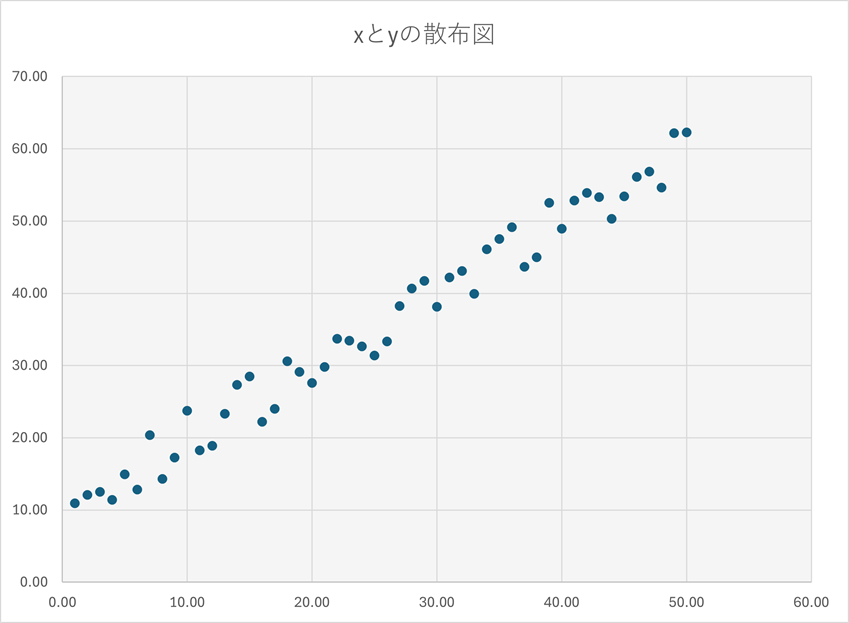
続いて、最小二乗法による計算から、aとbを求めます。計算は省きますが、 a = 1、 b = 10 という結果が出たとしましょう。これにより、このデータは、全体として y = x + 10 という傾向があることが突き止められたわけです。この一次方程式を、オレンジ色の線で描画してみます。
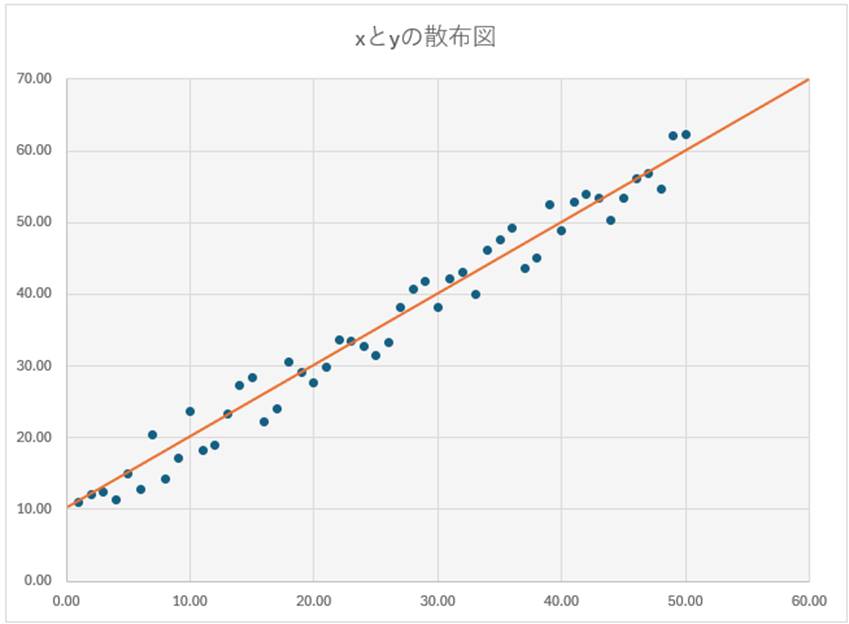
鈴木:グラフにすると分かりやすいですね。座標データの傾向が、目で見て分かります。これを固変分解の言葉で言えば、固定費が10で、単位当たりの変動費が1ということですね。
機械学習というと、非常に専門的な数式を扱うのだと思っていましたが、管理会計の考え方にも関係があったのですね。
外山:今の流れで言うと、aとbを求めるプロセスこそが、「学習」なのです。
もちろん、機械学習はこれだけで終わりません。学習が完了したら、次のプロセスは、「予測」です。 y = x + 10 という数式を導くことができれば、未知のxが与えられても、yを予測することが可能なのです。
鈴木:xが60という学習データにない値が与えられても、yは70前後だと学習によって予測できるということですね。
外山:この予測というのが重要です。「AIは学習したことしか分からない」という常套句がありますが、学習していないことでも、学習データから合理的に予測できることなら「分かる」のです。だからこそ、機械学習は数学であるといえるのです。
鈴木:会計監査業務でも、不正仕訳検知AIを使ったことがありますが、大量の仕訳データを学習させ、仕訳の不正リスクを予測するというものでした。データの学習によって、未知のデータに対しても予測できるようになったわけですね。
外山:学習から予測という流れは機械学習全体に共通するもので、機械学習の本質が詰まっていると言えます。さらに複雑な手法を扱う場合でも、基本に立ち返ることをオススメします。
鈴木:さらに複雑な手法というのは、例えばニューラルネットワークでしょうか?
ニューラルネットワークの仕組み
外山:ニューラルネットワークは、現在の機械学習の代表例ですね。
前回、第2次AIブームの中で、ニューラルネットワークを学習させることができるようになったものの、多層構造にすると学習がうまくいかなかったというお話しをしました。長らくニューラルネットワークの性能は頭打ちになっていたのですが、このような学習に関する問題を解決した技術こそが、「ディープラーニング(深層学習)」です。ディープラーニングの登場によって、多層の、大きなニューラルネットワークの学習が可能になったのです。
鈴木:前回、ニューラルネットワークというのは、多層になり、規模が大きくなるほど賢くなると聞きました。ここからAIの性能が一気に向上することが期待できますね。
外山:では、ここでニューラルネットワークの仕組みについても深掘りしてみましょう。
最も単純なニューラルネットワークでしたら、あまり難しくありません。最初は戸惑うと思いますが、必要な数学も四則演算だけなので、少しお付き合いください。
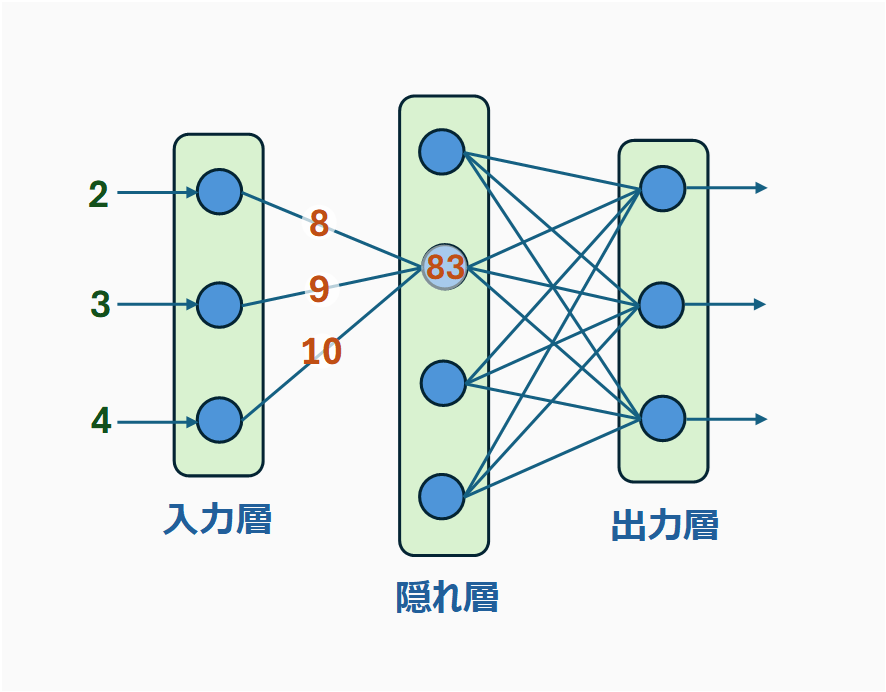
まず、この図をご覧ください。
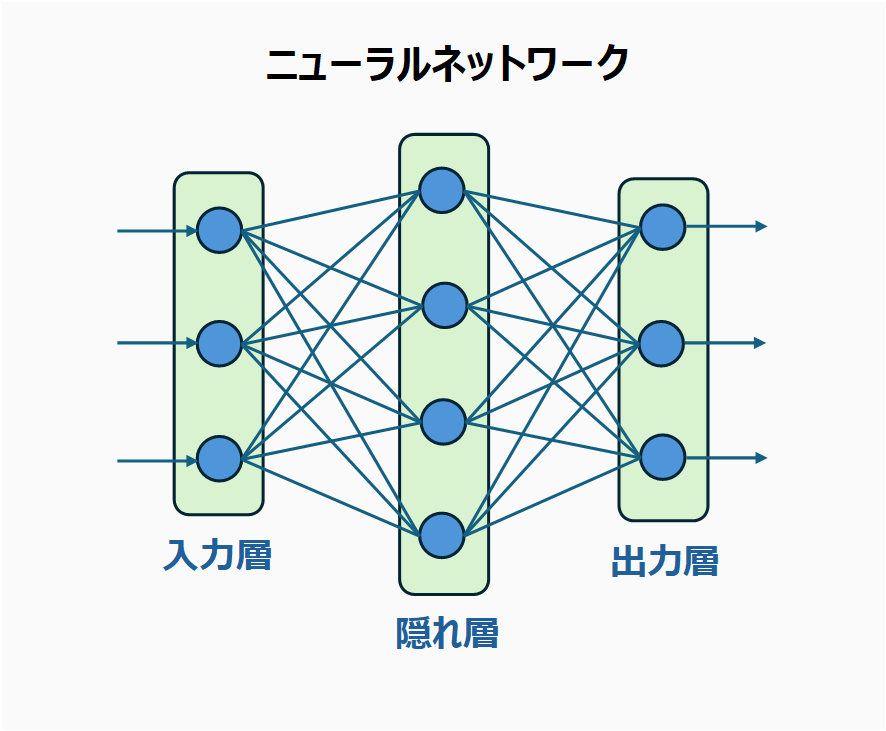
これは3層のニューラルネットワークです。淡い緑が層で、入力層、隠れ層、出力層と呼びます。そして、各層には青い丸がありますが、これらがニューロンのようなもの、丸同士を結んでいる線がシナプスのようなものです。
この入力層からデータが入ってきます。そして、各線を辿って隠れ層に進み、隠れ層内の丸を経由して、また線を辿って出力層に進みます。最後は出力層から出ていくという流れになります。
鈴木:入力されたデータが、各層を経由して、最終的に出力されるというイメージは掴みました。具体的には何が行われるのですか?
外山:まず、入力層には、数値データが入ってきます。続いて、この線の部分には、「重み」と呼ばれる数値が設定されているのですが、入力層から入ってきた数値と、この重みを掛け合わせる(乗算)のです。これについても、図にしてみましょう。一気に行うと混乱するので、隠れ層の1番上の丸に向かう線だけに注目します。
入力層には2、3、4という数値が入ってきて、各線には、5、6、7という重みが設定されています。
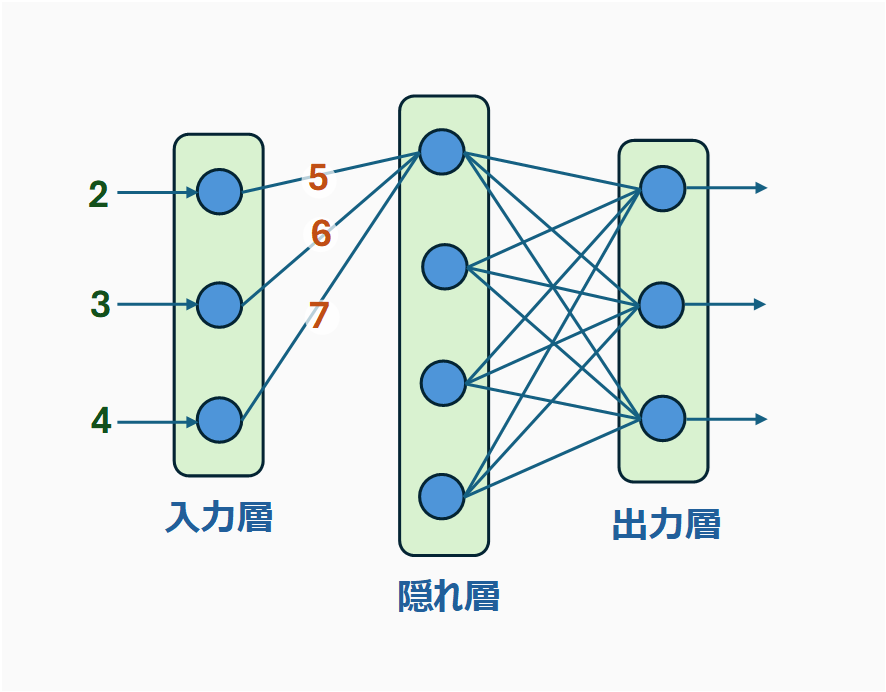
鈴木:それぞれの値を掛け合わせるのですよね?ということは、以下のような計算になります。
2×5=10
3×6=18
4×7=28
ここまでは難しくないですね。
外山:次に、隠れ層の丸に到達した際に、それら全ての値を足し合わせます(加算)。この場合は、10+18+28で、56という答えが導かれます。
鈴木:入力層から入った、2、3、4という値が、隠れ層に到達したとき、56になったということですね。
外山:この56という数値に対して、活性化関数というものを適用します。ようするに、数学的な処理をして、値を変換するということです。そして、変換後の値が隠れ層から出て、また各線に設定された重みを掛け合わせて、出力層に進み、加算される…という処理をするわけです。
理解の確認のため、隠れ層の上から2番目の丸に進むルートも見てみましょう。
この場合は、2×8=16、3×9=27、4×10=40となり、合計は83です。
鈴木:計算自体は難しくないですね。単純な構造のニューラルネットワークだからというのもあるのでしょうが。
ニューラルネットワークを行列で表す
外山:このような計算を、全ての丸(ニューロン)と線(シナプス)に対して行います。
ところで、第2回の講義で、「ニューラルネットワークは行列として計算でき、行列計算は並列処理をすることができるため、GPUによって計算の高速化が図れる」という趣旨の説明をしました。それについても解説しましょう。
鈴木:お願いします。
外山:まず、最初の例に当てはめます。入力した数値に重みをかけ、最後にそれらを足し合わせるという処理は、以下のような行列の積(内積)の形で書くことができます。
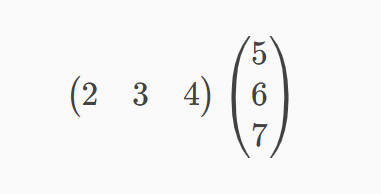
鈴木:行列の計算は懐かしいですね。この計算は2×5+3×6+4×7と書けるので、56となります。
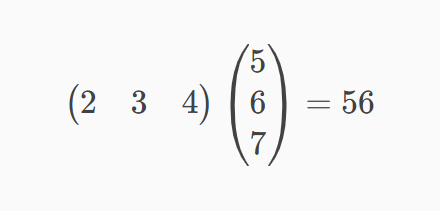
たしかにニューラルネットワークの計算と全く同じ処理ですね。このように行列に繋がるのですか。
外山:同様に、隠れ層の上から2番目、3番目、4番目の丸についても計算できますが、これら全てを、一つの行列計算式で書くことができます(3番目に繋がる重みは、11、12、13。4番目に繋がる重みは14、15、16としました)。
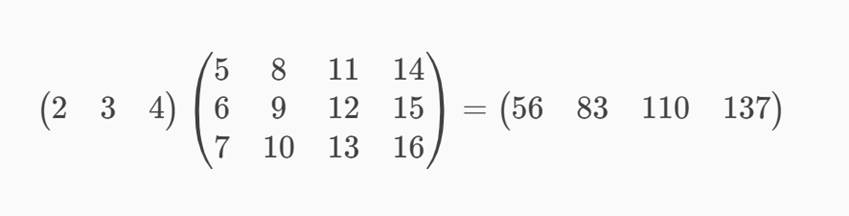
このように、一つの式で、入力層から隠れ層に進む計算を表すことができました。ここで重要なのは、56、83、110、137という各値を求める計算は、互いに独立だということです。つまり、56を求めてから83を求める、といったような順番関係はなく、同時に計算することが可能なのです。
鈴木:2×5+3×6+4×7=56
2×8+3×9+4×10=83
2×11+3×12+4×13=110
2×14+3×15+4×16=137
これら4つの計算は順に解く必要はないので、同時に行うことができるということですね。
外山:そうです。ここで、GPUは同時に計算することが得意だということを思い出してください。これを並列処理ともいいます。行列(ニューラルネットワーク)の計算は並列処理が可能なので、GPUと非常に相性が良かったのです。これにより、エヌビディア社のGPUの需要が高まったわけですね。
鈴木:そのように繋がっていくのですね。よく分かりました。
ただ、この例では、重みとして5、6、7などという値があらかじめ設定されていました。この値はどこから来たのでしょうか?
外山:その値は、「学習」によって決まります。大量のデータを用いて計算することによって、これらの重みを決定するのです。ニューラルネットワークの学習のプロセスはかなり複雑なのですが、データからパラメーター(重み)を計算するという流れ自体は、先ほどの最小二乗法と同じです。
つまり、いま行った流れは「予測」のフェーズなのです。本来は、この前に、パラメーターを決める「学習」のフェーズがあるということですね。
ニューラルネットワークのデータ形式
鈴木:他にも疑問があります。ニューラルネットワークが、このような計算を行うことは分かりましたが、入力する値も、出力する値も、どちらも数値ですよね。最近のAIは画像や音声、文章なども扱うことができるはずですが、それらはどのような処理がなされているのでしょうか?
外山:画像はピクセル(画素)の組み合わせなので、赤成分、緑成分、青成分、透明度を、[160, 110, 52, 255]などという数値にできますね。音声は、音の波形を数値として表します。
言語についてはピンと来づらいと思いますが、言語を数値に変換する技術があるのです。ニューラルネットワークは数値しか扱えませんが、逆に言えば、数値にさえ変換できれば、理論的にはどのようなデータでもニューラルネットワークで扱うことができることになります。
鈴木:数値に変換して扱うというのがポイントなのですね。ニューラルネットワークが行うことが「計算」である以上、言われてみれば当然のことかもしれません。
外山:最終的な出力についても、例えば、出力層から[13, 79, 8]という数値が出力されたとしましょう。これらがそれぞれ、イヌ、ネコ、ネズミを表す確率だとして扱えば、この出力結果は「ネコを表す確率が一番高い」と解釈できます。このように、単に数値データとして扱うだけでなく、カテゴリーデータとして扱うこともできるのです。
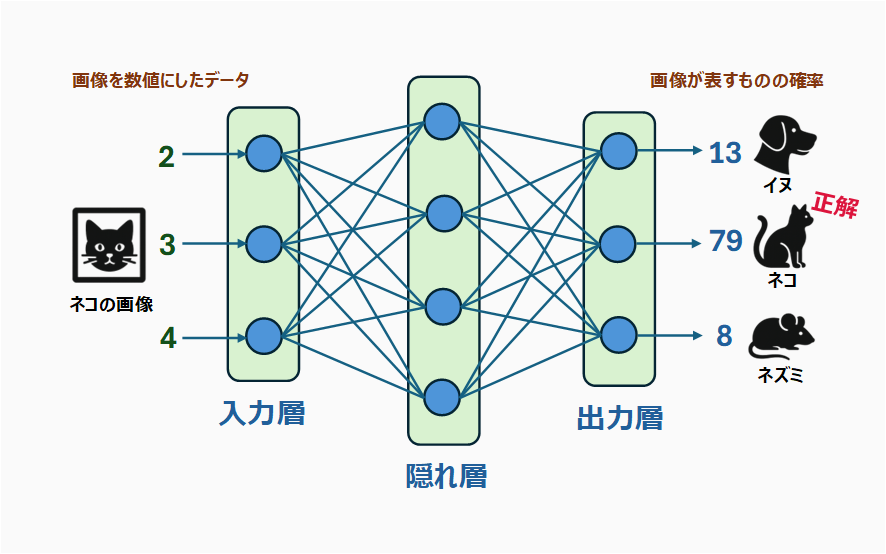
鈴木:この例は、画像データを入力したら、この画像に映っているものはネコだと判定された、という場合ですね。
そのように考えると、数値しか扱えないということは不便ではなくて、むしろ非常に表現力が豊かだと言えそうです。ニューラルネットワークが広く利用され、大きな成功を収めている理由が見えてきました。
外山:次回はいよいよ生成AIが登場します。従来のAIと何が違うのかという点もお話ししますので、楽しみにしていてください。

外山 哲郎
有限責任パートナーズ綜合監査法人
金融系、ゲーム系、など幅広い分野でスマートフォンアプリやWebサイトの開発に携わる。 2017年からAI業務に従事。データ分析や、医療の分野でのAI活用の研究・開発などに携わる。 ライターとしても活動(ニコニコニュース(ニコニコ動画))。 2024年7月 有限責任パートナーズ綜合監査法人入所。 現在は、IT専門家として監査業務に携わる他、法人内のDXおよびAI活用を推進している。

鈴木 爽矢
有限責任パートナーズ綜合監査法人
2022年大学3年生時に公認会計士試験合格。 大学時代にはCPA会計学院で監査論のチューター及び広報部のマーケティング業務を行う。 その後大手監査法人、コンサルティング会社を経て現職の有限責任パートナーズ綜合監査法人に入所。 現在は主に、IPO準備会社や上場企業の会計監査に従事し、財務デューデリジェンスなどの非監査業務にも携わっている。