【特別コラム連載】会計ファイナンス人材×AI第6回 実用的なAI用語を理解しよう

目次
Pythonとは
外山:みなさん、こんにちは。前回までで、AIの歴史を一通り学びました。今回はAI関連の用語を学びつつ、今までお伝えしたことの補足をしたいと思います。
まず、一般的に、ソフトウェアを開発する際には、プログラミング言語を用いてプログラムを書きます。その点は、AIであっても変わりません。
鈴木:よろしくお願いします。それではさっそく質問なのですが、AIについて勉強しようとすると、Python(パイソン)という用語が出てきます。プログラミング言語だということは知っていたのですが、なぜAIの開発にPythonが使われているのか、その理由を知りたいです。
外山:日本ではPythonはあまり使われてこなかったため、新しい言語だと思われがちですが、実は1991年に開発されたもので、有名なJava(1995年開発)よりも歴史が古いです。Pythonを開発したのは、グイド・ヴァンロッサムというオランダ人で、長らくGoogleで働いていたことでも知られています(Pythonの名前の由来は、イギリスのコメディグループ「モンティ・パイソン」といわれています)。
鈴木:意外と歴史が古い言語なのですね。
外山:そうなのです。先ほど、日本ではあまり使われてこなかったと言いましたが、アメリカでは広く使われている言語です。初心者にも使いやすいため、最初に覚えるべきプログラミング言語として推奨されてきました。その理由としては、読みやすく、誰が書いても同じような書き方になるという点が大きいです。書き方が多様な言語だと、他人が書いたプログラムを読み解くのが大変ですからね。
また、一般に、プログラムを動かすにはコンパイル(プログラムを実行ファイルに変換する処理)を行う言語が多いのですが、Pythonはコンパイル無しですぐに実行できるため、ちょっとした実験や作業に使うには、非常に使い勝手が良いのです。
鈴木:一般論として使いやすい言語なのだということは分かりましたが、AI向きの特性もあるのでしょうか?
外山:Pythonは処理速度が遅く、これはAIを動かすうえで致命的な欠点と言えます。
それにも関わらずPythonがAI開発において支配的な地位を占めることができた理由として、他人が書いたプログラムを、手軽にインポートできる仕組みがあるという点が挙げられます。つまり、優秀な研究者やエンジニアが開発したAI関連のプログラムをインポートすることにより、誰でも手軽にAIを動かすことができるというわけです。
鈴木:そのような特性があったのですね。AIの本場であるアメリカでよく使われている言語だという点も大きいのでしょうね。利用者が多ければ、優れたプログラムも多いと思われるので。とはいえ、処理速度が遅いという問題は残っていますよね。
外山:処理速度についてもさまざまな改良がありましたが、一番大きいのは、エヌビディア社が開発したCUDAというソフトウェアを用いることで、GPUを使って計算できるようになったことでしょうね。
GPU(Graphics Processing Unit:画像処理装置)とは、画像や動画の処理を行うための半導体チップのことですが、大量の計算を同時(並列)に行うことができるという特性があります。AIで行われている行列計算は並列に処理できるので、GPUと非常に相性が良いのです。
CUDAの登場により、Pythonで書かれた処理をGPUで動かすことが楽になりました。これにより、Python自体の処理速度の遅さも気にならなくなりました。
回帰と分類とは
鈴木:次に機械学習についてですが、自分で勉強をしようとしても、耳慣れない用語が多くて戸惑います。エンジニアでなくても押さえておくべき機械学習用語を解説してください。
外山:機械学習とは、与えられたデータを学習し、そのデータのパターンや傾向、特徴などを発見するという技術でした。学習をすることにより、予測できるようになるという点も重要でしたね。
その予測に関する用語として、回帰と分類を解説します。
まず、回帰についてです。これは一般的には「もとの位置や状態に戻ること」を表す言葉ですが、機械学習の分野では、「予測対象が数値であること」を指します。すでに『第4回 機械学習とは何か』でも、最小二乗法を用いて一次方程式を導きましたが、あれは回帰の代表例です。
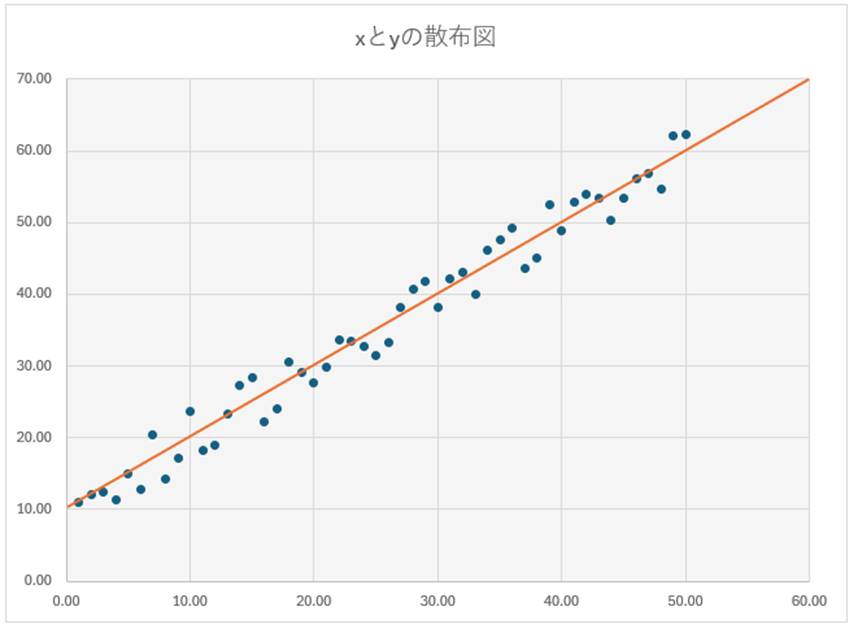
外山:このグラフでは、大量の座標データから、y = x + 10 という式を導き出しています。機械学習的に言えば、この式を用いることによって、特定のxの場合の、yの値を予測することができるようになったわけです(ちなみに、このように、一次方程式を導くことを、機械学習の分野では線形回帰と呼ぶ場合が多いです。線形というのは、グラフにしたときに直線で表せる関係をいいます)。
ここで注目すべきは、予測値であるyは、数値であるということです。
鈴木:たしかに、y = x + 10という式は、数値を入力して、数値を出力(予測)しています。これが回帰なのですね。
回帰という言葉の響きには違和感がありましたが、やっていることは理解しやすいです。逆に、数値以外を予測するという方がイメージが湧きませんね。
外山:では、続いて分類の説明をしましょう。こちらは予測対象がカテゴリーになります。
具体例をお見せしましょう。例えば、ネコ、ネズミ、ヘビという3種の動物を、それぞれ5匹ずつ捕まえてきて、その各個体の体長と体重を散布図にプロットしたとします。分かりやすいように、ネコを青、ネズミを赤、ヘビを緑に着色してみます。
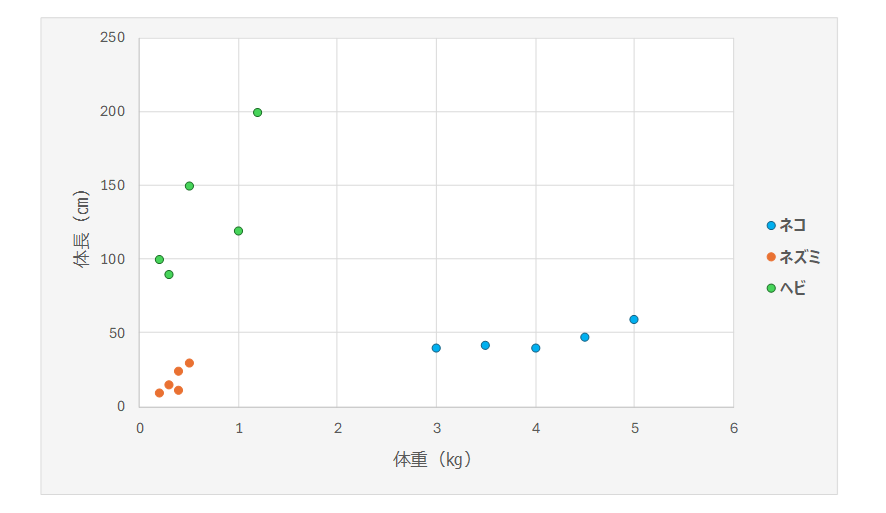
外山:この散布図を見て、傾向やパターンなどを発見できますか?
鈴木:動物によって、分布に偏りがありますね。大まかには、以下のような枠の中に収まる傾向がありそうです。
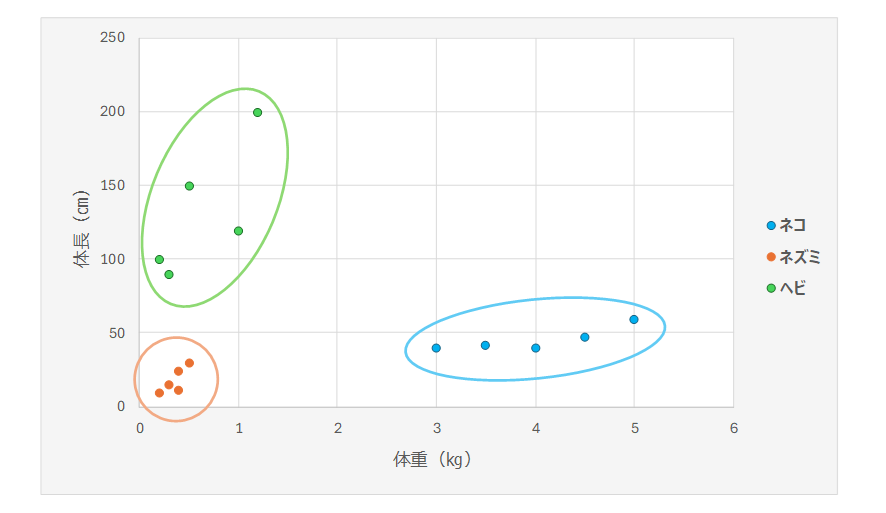
外山:そうですね。いま、鈴木さんはプロットされた座標情報を眺めることにより、データ全体の傾向やパターンを発見しました。これは機械学習の言葉でいえば、「学習した」ということになりますよね。
では次に、体長が60㎝で、体重が4㎏の動物が見つかった場合、それは何だと思いますか?
鈴木:数値が分かっているので、散布図にプロットしてみます(黒い点)。先ほど描いた青い枠の中に入っていることから、ネコだと予測することができますね。
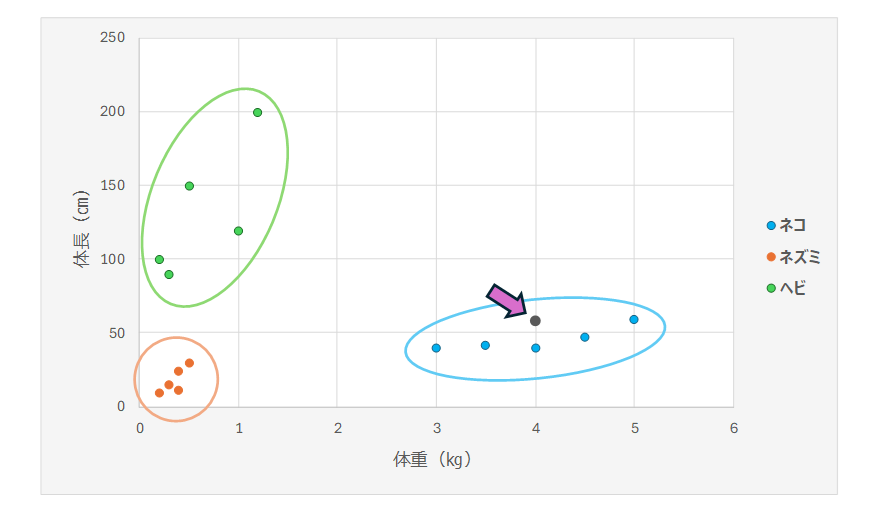
外山:いま、鈴木さんは、学習した知識を活かして、未知のデータをネコだと予測しました。これが分類ということです。「どの動物に属するのか」という、カテゴリーを予測したわけです。
今の一連の流れは人間の「直観」によって行われたわけですが、データから導かれた数式を解くことよって行われたのなら、機械学習だと呼べそうです。
鈴木:そういうことですか。数値ではなく、カテゴリーを予測するということの意味が分かりました。最小二乗法では、この問題を解くことはできないと思われますが、分類のための機械学習の手法があるということでしょうか。
外山:そうですね。今回は全て解説できませんが、このような分類問題を解くためには、ロジスティック回帰、決定木、サポートベクターマシン、ニューラルネットワーク…などの手法が考えられます。
鈴木:ニューラルネットワークは、分類のための手法だったのですね。
外山:実は、ニューラルネットワークは、回帰も分類も行うことが可能なのです。この柔軟性がニューラルネットワークの特徴だとも言えます。例えば、前回お見せした、画像の識別のためのニューラルネットワークを見てください。予測しているのは、どの動物なのかというカテゴリーです。つまり、これは分類の例となります。
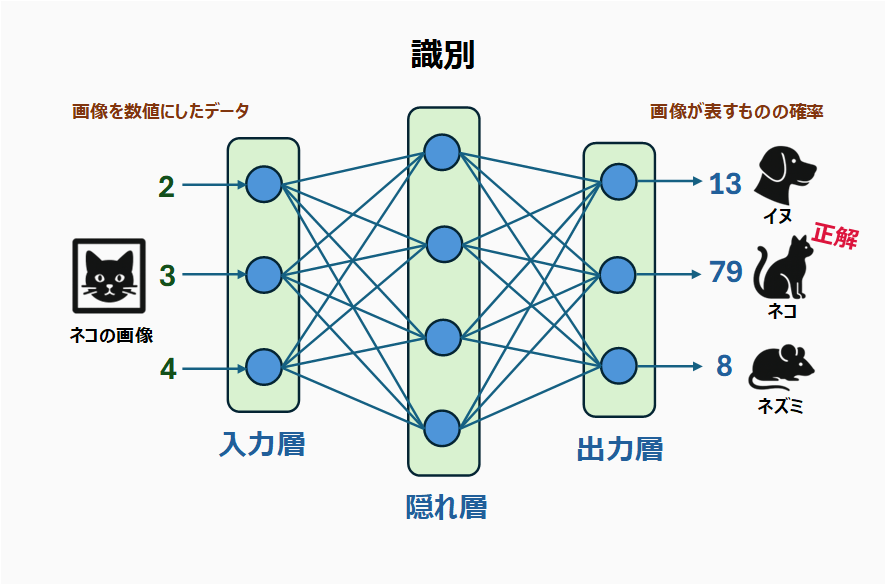
外山:それとは対照的に、生成の例では、画像のピクセルの色を表す数値を予測しました。全ピクセルの色が予測できると、全体としてネコの画像が現れるわけですが、予測しているのはあくまで個々の数値です。つまり、こちらは回帰の例となるわけです。
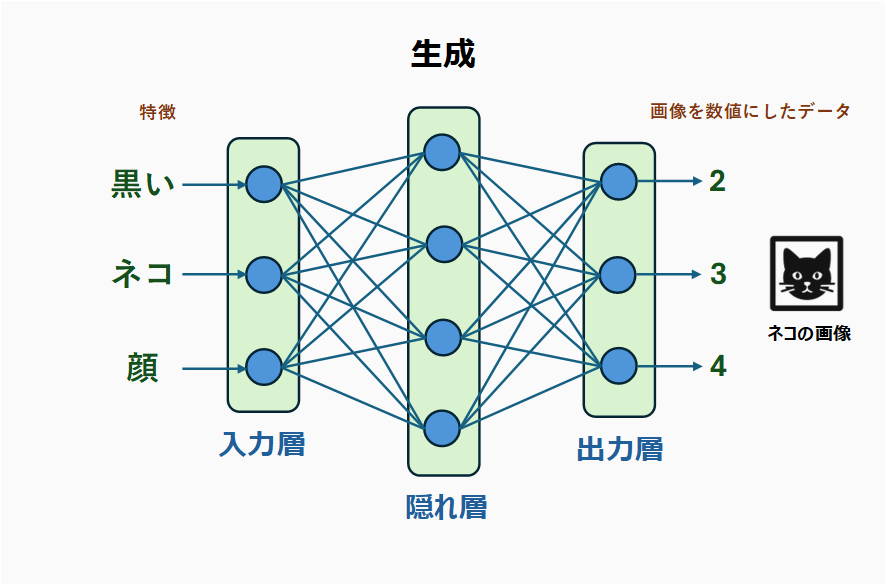
鈴木:識別の方も数値を出力しているので混乱しましたが、識別の出力層のニューロンの一つひとつが表すものは、「動物の種類」というカテゴリーですね。たしかに分類だと言えそうです。
外山:機械学習を行う場合、予測するものが数値なのかカテゴリーなのかという点に注意するようにしてください。それによって、適切な学習手法も変わってきますので。
教師あり学習と教師なし学習とは
鈴木:回帰でも分類でも、機械学習である以上、入力データと出力データのペアがあり、それらを学習するという流れは一緒なのですよね?
外山:たしかに、多くの場合、学習用のデータは入力と出力がセットになっていますが、そうではないものもあります。では、教師あり学習と教師なし学習という言葉も学んでおきましょう。
まず、教師あり学習というのは、いま挙げたような、入力と出力をセットにして学ぶものです。線形回帰の例は、xが入力で、yが出力ですね。先ほどの分類の例でも、体重と体長を入力にして、どの動物かというカテゴリーを出力しました。
出力データのことを、正解データと呼ぶこともあります。特定の入力値に対応する正解を学ぶわけです。正解が与えられた場合が、教師あり学習だと言い換えることもできます。
鈴木:教師というのは、正解のことだと考えれば良さそうですね。教師あり学習の方は分かりやすいです。今までの機械学習のイメージ通りですから。逆に、教師なし学習というのは、正解データが無いということですか?
外山:そうです。正解が与えられていなくても、機械学習によって正解を発見できるわけです。
初歩的な教師なし学習の例としては、K平均法という手法があります。いわゆるクラスタリングと呼ばれるもので、似た特徴のデータをまとめることができるのです。
例えば、先ほどのネコ、ネズミ、ヘビの分類の例で考えましょう。教師あり学習の場合、体長と体重という入力データと、それがどの動物を表すのかという正解データをセットにして学習します。
他方、K平均法(教師なし学習)の場合、それぞれの入力値が何を表すかという情報は与えず、データを3つに分けるということだけ決めておいて、あとは各座標同士の距離が近いものをまとめることにより、データを3つのクラスターに分類することができるのです。この計算する過程が、学習に当たります。
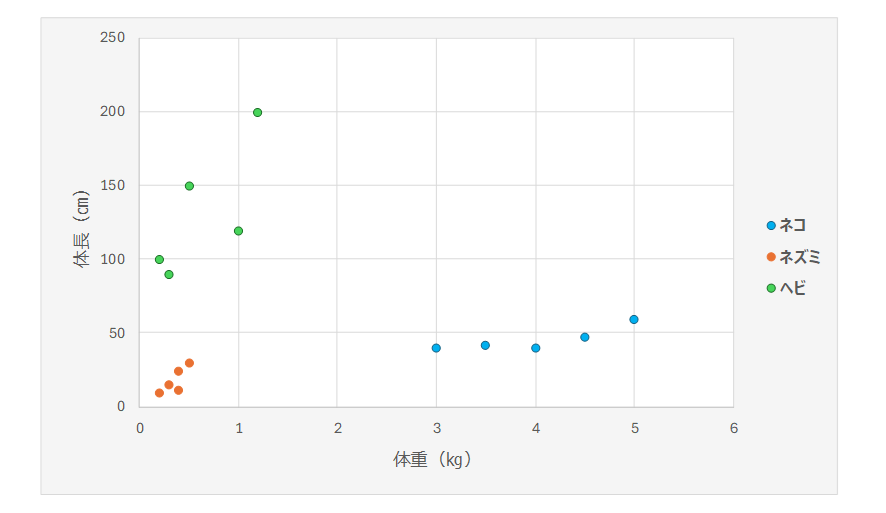
鈴木:各座標同士の距離を地道に計算することで、数学的に3つのまとまりを導くことができるのですね。たしかに、どの点がどの動物に該当するかという正解がなくても、データを3つに分類すること自体はできそうです。
オートエンコーダーとは
鈴木:ちなみにですが、ニューラルネットワークの場合は、入力層と出力層があり、それぞれに入力データと正解データが対応するものだったと思います。ということは、教師あり学習だけだという理解で良いでしょうか?
外山:いえ、ニューラルネットワークでも教師なし学習をする場合があります。それがオートエンコーダーという手法です。
鈴木:業務で、会計データの異常検知を行うAIを使ったことがありましたが、たしかオートエンコーダーという仕組みが使われていると聞いた記憶があります。
外山:まさにそれですね。オートエンコーダーは、一般的に異常検知に用いられることが多いです。簡単に仕組みを説明しましょう。
先ほどおっしゃったように、ニューラルネットワークでは、入力層に入力データ、出力層には正解データを与え、両者の対応関係を学習するのが普通です。それに対し、オートエンコーダーは、入力データしか与えません。正解という考え方がなく、入力データと同じものを出力するよう学習するのです。
鈴木:入力データと出力データが同じなのですか。不思議なことをするのですね。
外山:これだけ聞いても、意義が分かりづらいと思いますが、入力したデータ自体の特徴を学習するという点がポイントです。
例えば、オートエンコーダーにネコの画像を大量に学習させる(ネコの画像を入力し、同じ画像を出力させる)と、内部にはネコの特徴が蓄えられていくのです。これをネコ・オートエンコーダーと命名しましょう。ネコ・オートエンコーダーは、単に入力データと同じものを出力するわけではありません。ネコの特徴を持った画像を出力するようになるのです。
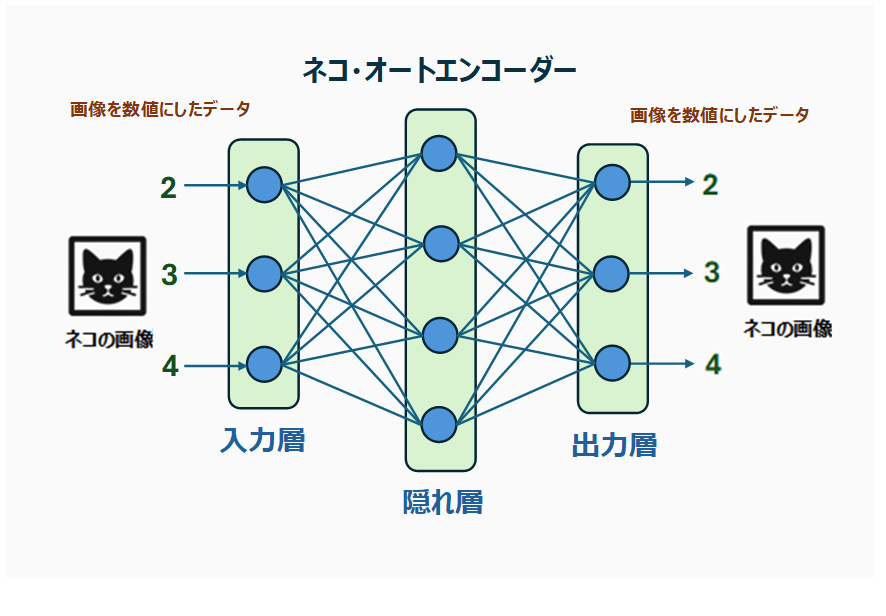
外山:これを使って異常検知をしてみます。この場合、ネコの画像が正常な画像ということです。
このネコ・オートエンコーダーは、未知の画像を入力した場合でも、それがネコの画像であれば、入力した画像とほぼ同じものを出力します。ネコの画像にネコの特徴を持たせても、特に影響はないですからね。
鈴木:では、ここにイヌの画像、つまり異常値を入力すると、どうなるでしょうか。
外山:ネコ・オートエンコーダーの特性から、ネコの特徴を持った画像を出力するので、ただのイヌではなく、ネコの特徴を持ったイヌが出力されることになりそうです。つまり、イヌの画像を入力した場合、入力した画像と同じものは出力されないということです。
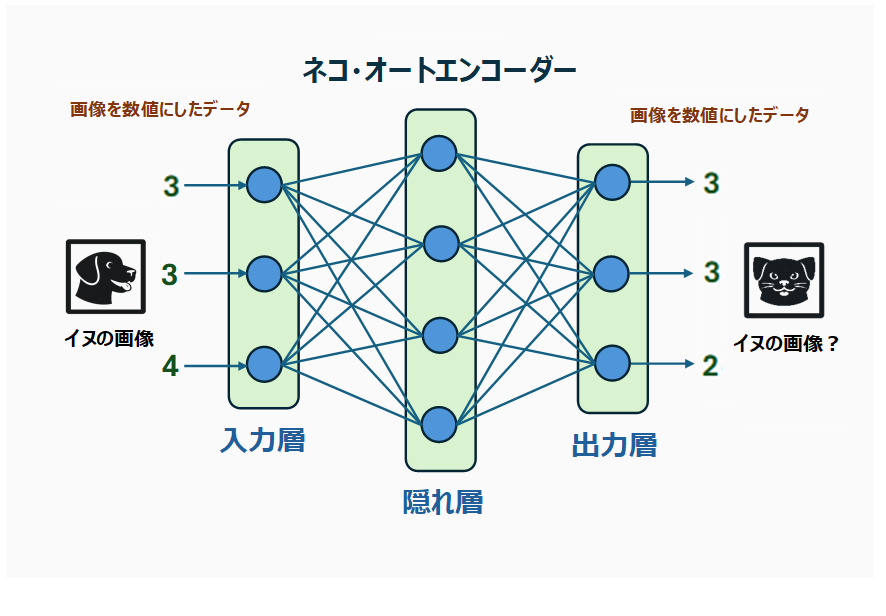
外山:オートエンコーダーを異常検知器として使いたい場合、学習段階では、正常なデータを大量に学習させるのです。それにより、正常なデータが入力されれば、ほぼ同じものが出力され、異常なデータが入力されれば、かなり異なるものが出力されるオートエンコーダーができあがります。
あとは、入力と出力の差分を取り、その差が一定以上の場合は異常だと判定する仕組みを実装すれば、異常検知器ができます。
鈴木:異常検知の裏では、このようなことが起きていたのですね。オートエンコーダーが、ニューラルネットワークを利用した教師なし学習だということも理解できました。
外山:今回は細かい話が多くなってしまいましたね。次回からは、いよいよAIの使い方について、実践的な内容をお話ししたいと思います。

外山 哲郎
有限責任パートナーズ綜合監査法人
金融系、ゲーム系、など幅広い分野でスマートフォンアプリやWebサイトの開発に携わる。 2017年からAI業務に従事。データ分析や、医療の分野でのAI活用の研究・開発などに携わる。 ライターとしても活動(ニコニコニュース(ニコニコ動画))。 2024年7月 有限責任パートナーズ綜合監査法人入所。 現在は、IT専門家として監査業務に携わる他、法人内のDXおよびAI活用を推進している。

鈴木 爽矢
有限責任パートナーズ綜合監査法人
2022年大学3年生時に公認会計士試験合格。 大学時代にはCPA会計学院で監査論のチューター及び広報部のマーケティング業務を行う。 その後大手監査法人、コンサルティング会社を経て現職の有限責任パートナーズ綜合監査法人に入所。 現在は主に、IPO準備会社や上場企業の会計監査に従事し、財務デューデリジェンスなどの非監査業務にも携わっている。