【特別コラム連載】会計ファイナンス人材×AI第5回 生成AIとは何か

外山:みなさん、こんにちは。今回はいよいよ生成AIが登場します。前回までのAIの歴史の話が、最先端の生成AIへと繋がっていくわけです。
鈴木:よろしくお願いします。監査業務でも、情報収集、外部データ解析などで、生成AIを補助的に使用しています。
最近では、AIと言った場合、ほぼ生成AIを指すことが多いですね。
外山:以前は「ジェネレーティブAI」と呼ぶこともあったのですが、最近は「生成AI」で統一されていますね。文章、画像、動画などを生成することができるAIを指すわけですが、創作活動は人間にしかできないと長らく考えられていたため、社会に与えたインパクトは大きかったです。
鈴木:生成AIは、従来のAIとは全く別物だと考えた方が良いのでしょうか?
外山:いえ、生成AIも、機械学習の一分野であることは変わりません。機械学習は、与えられたデータをAIが学習し、そのデータのパターンや傾向、特徴などを発見するという技術でした。学習をすることにより、予測できるようになるという流れも勉強しましたね。そういった点は、生成AIでも変わらないのです。
鈴木:生成AIの場合、文章や画像を新たに生成するのですから、パターンの発見や予測とは、少し違うものだという印象を受けます。
外山:では、その説明のため、まずは前回学んだ画像認識(識別)AIを振り返りましょう。大量の動物の画像を学習することで、未知の画像を与えられても、それが何であるかを予測できるようになったものです(実際の画像認識のニューラルネットワークは、これよりずっと複雑な構造だということにご注意ください)。
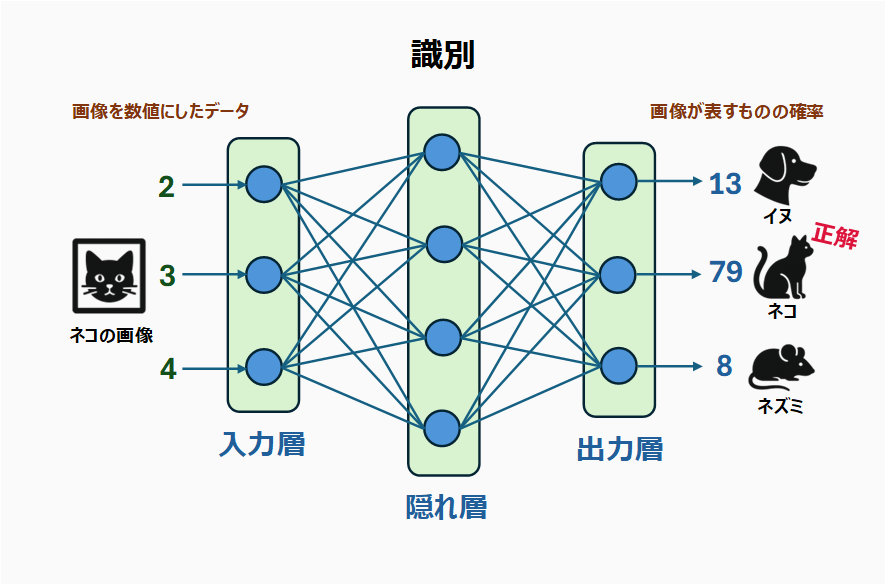
鈴木:画像のデータを数値に変換して入力し、大量の計算をしながらニューラルネットワークを通り抜け、最終的には、この画像が表すものの確率が出力されるというものですね。この例では、画像に映っているのは、ネコだと識別されました。
外山:次は「生成」の場合を考えてみましょう。
生成するためには画像を出力する必要がありますが、識別の際の入力と同様、数値化された画像データを出力すれば良いわけです。「黒い」、「ネコ」、「顔」といった情報から、それに該当する特徴を持った画像を予測するわけです。
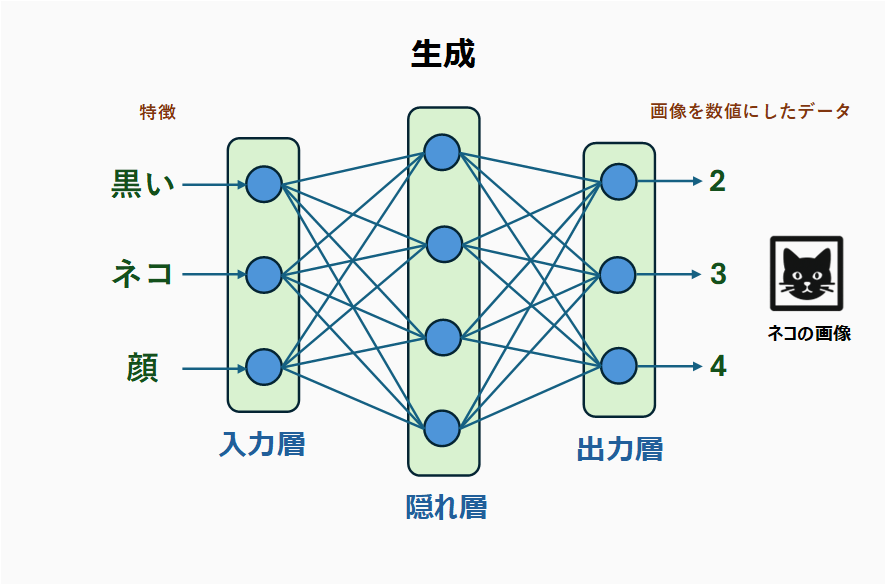
鈴木:こうして見ると、識別の場合の逆だと考えられますね。ただ、この「黒い」、「ネコ」、「顔」といった情報をあらかじめ数値に変換して入力する必要はありますよね。
外山:数値にさえできれば、どのようなルールでも良いのです。例えば、「黒い」なら-1、「白い」なら1といった具合に、2値の形式で入力することもできますし、あとから述べるように、言語を直接数値化する方法もあります。
鈴木:なんらかのルールで、数値にさえできれば良いのですね。
生成AIが、従来のAIの延長線上にあるものだということも理解できました。
●画像生成AIの歴史
外山:では、まずは画像生成AIのお話しをしましょう。2014年にGAN(敵対的生成ネットワーク)と呼ばれるニューラルネットワークが登場して、画像生成AIが盛り上がっていきます。
GANは、今お話ししたような「識別するAI」と「生成するAI」の両方の機能が備わっているのが特徴です。生成側が画像を生成し、識別側は、それが本物の画像か、あるいは生成側のAIにより生成されたニセモノかを識別するという構造なのです。
生成側は、識別側を欺くため、より本物に近い画像を生成すべく学習し、識別側は、生成側のウソを見抜こうと学習するのです。このように、2つの相反した目的のAI(ニューラルネットワーク)が、争いながら賢くなっていく様子が、「敵対的」という名の由来です。
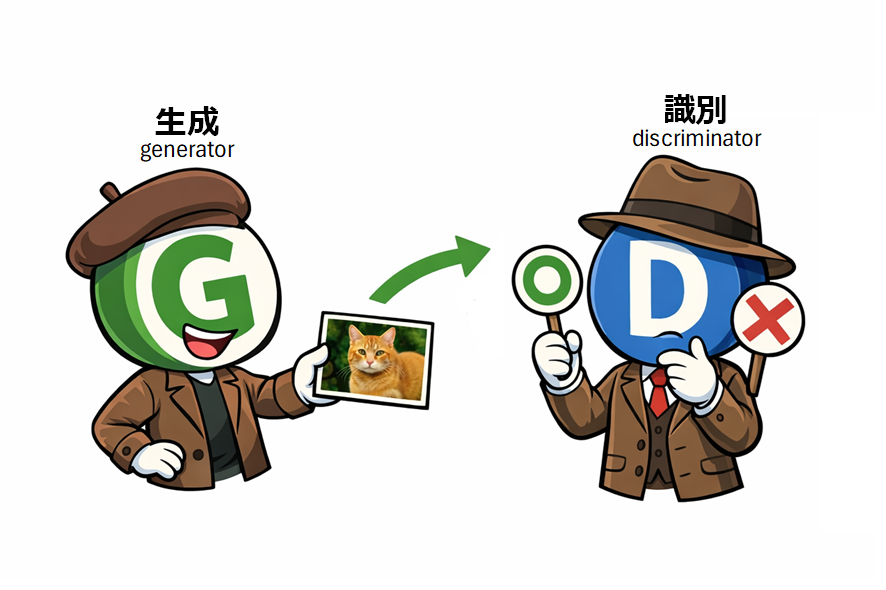
鈴木:かなり凝った構造ですね。生成側と識別側の2つのAIがあるということですが、生成側の方は、まさに生成AIそのものだと言えそうです。
外山:GANは画期的でしたが、学習の構造が複雑だということもあり、成果物が不安定でした。実用的な画像生成AIが作れるようになったのは、拡散モデルの登場が大きかったです。これは、現在まで続く画像生成の王道ともいえるモデルです。
拡散モデルの方が、仕組みはシンプルです。基本的には生成側しかありません。
学習のための画像を用意して、そこに少しずつノイズを加えていき、最終的にはランダムなノイズのみの画像にします。続いて、その画像のノイズを徐々に取り除いていき、元の画像を復元します。このようなプロセスを繰り返して学習させるのです。最終的には、ランダムなノイズ画像さえ与えれば、そこからさまざまな画像を予測(生成)することができるようになるわけです。
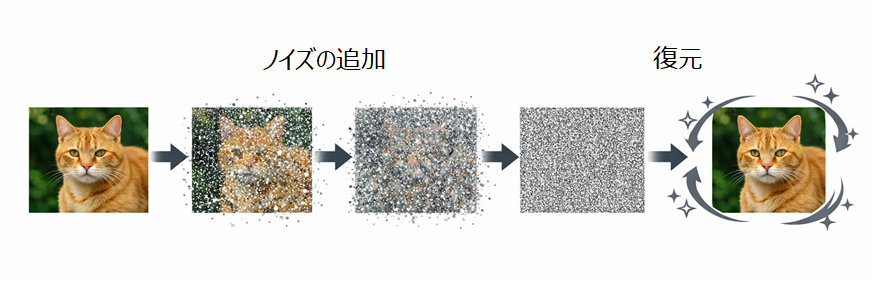
拡散モデルは成果物が安定しており、生成の自由度も高かったため、Stable DiffusionやDALL-E 、Midjourneyなど、多くの画像生成AIサービスに採用されました。
鈴木:画像生成AIでも、学習から予測という流れは共通しているのですね。
ChatGPTのような言語モデルも、このような学習を行うのでしょうか?
●言語モデルの歴史
外山:言語モデルは別の進化を辿ります。Googleの研究者チームが2013年に公開したword2vecというモデルがブレイクスルーでした。word2vecにより、単語を数値(ベクトル)に変換することができるようになったのです。
鈴木:数値にさえ変換できれば、ニューラルネットワークをはじめとする機械学習で用いることができますね。それは大きな進歩です。
外山:word2vecの段階では、単体の単語や、ちょっとした単語の組み合わせしか扱えませんでしたが、さまざまな興味深い性質があり、大きな話題となりました。例えば、イヌを表すベクトルが [2, 14]、ネコは [4, 16]、リンゴは [10, 10] と変換されたとしましょう。これらベクトル同士の角度が、単語の類似度と対応したのです。図に描いてみましょう。
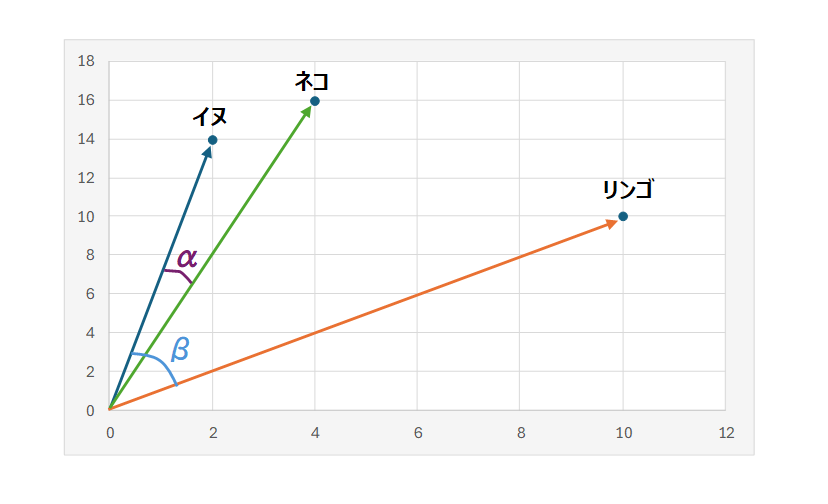
鈴木:イヌのベクトルと、ネコのベクトルが成す角度αは、かなり小さいようです。ベクトルの方向が近いということですね。この場合、イヌという単語とネコという単語の意味が似ているということでしょうか?
外山:そういうことになります。それに比べて、リンゴという単語のベクトルとイヌのベクトルが成す角度βは、比較的大きいようです。ここから、リンゴはイヌとはかなり意味が違う単語なのだということが可視化できました。
鈴木:面白いですね。ベクトル同士の方向のズレ(角度)を測ることで、単語の意味の近さを計算できるのですか。
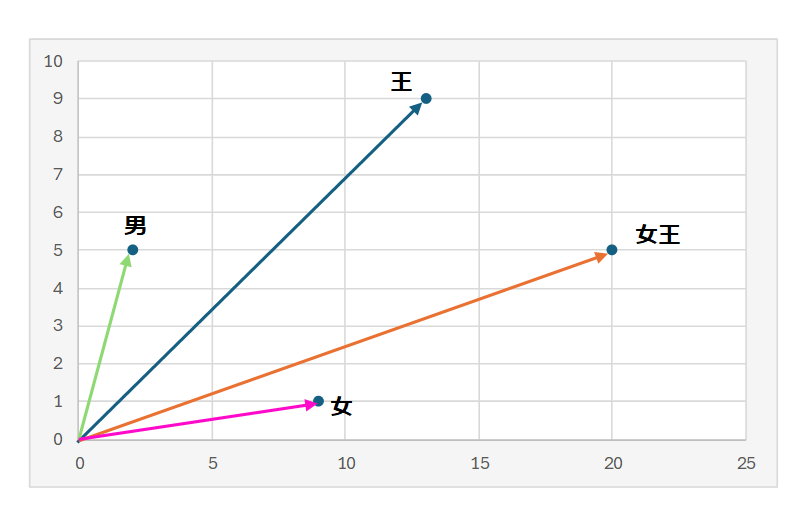
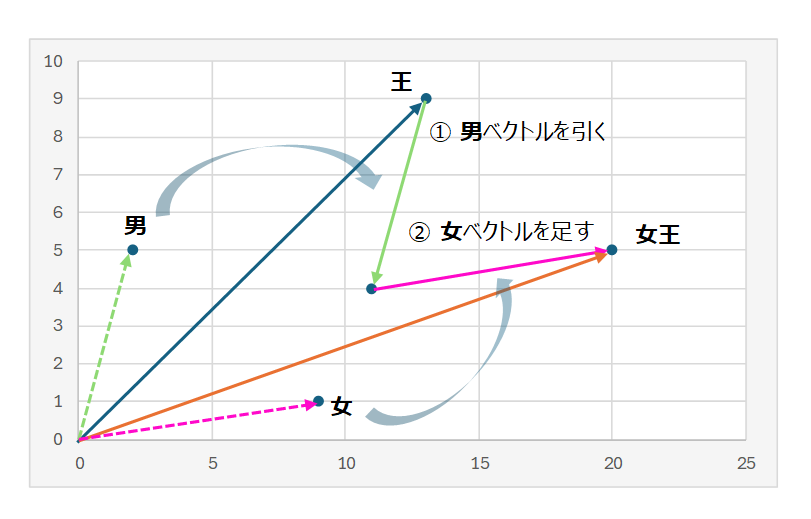
外山:単に類似度を測れるだけではありません。例えば、「王」という単語のベクトルから、「男」を引き、「女」を足し合わせると、「女王」のベクトルとほぼ一致するという有名な例があります。具体的には、以下のような計算をすることができるのです。
王 [13, 9] – 男 [2, 5] + 女 [9, 1] = 女王 [20, 5]
鈴木:単語の意味を計算できるというのは驚きです。
今の例では2つの数値で表す2次元のベクトルだったので、グラフに書くこともできましたが、実際はここまで単純ではないのですよね?
外山:そうですね。word2vecでは、だいたい数百くらいの次元数になります。
鈴木:数百次元のベクトルということですか…。それはグラフにするのは不可能ですね。そもそも数百次元というのはイメージが湧きません。
外山:数百次元を空間的にイメージしようとすると、頭が混乱してしまいます。これはあくまで数百個の数値が並んでいるだけだと割り切りましょう。いくら高次元のベクトルであっても、足し算や引き算は簡単にできますし、ベクトル同士の角度の計算もできます。次元数が多くても、身構える必要はないのです。
鈴木:大事なのは、単語を数値のまとまり(ベクトル)で表すことができて、それが単語の意味に対応しているということですね。word2vecの登場により、言語モデルの発展が期待できそうです。
外山:単語レベルでの言語を扱うことはできるようになりましたが、長い文章を扱うためには、さらに多くのハードルを越える必要がありました。文章は単語の羅列ではなく、その順序や、単語同士の結びつきなどを考慮しなければなりません。ちょっと単語の順序が変わっただけで、文章全体の意味も大きく変わってしまうからです。
閉塞を打ち破ったのは、トランスフォーマー(Transformer)というモデルです。これもword2vec と同様、当時のGoogleの研究者たちが発表しました。トランスフォーマーにはアテンション(注意機構)と呼ばれる機能があるのですが、これにより文章中の単語同士の関係性を把握できたのです。また、学習や処理が速い上、並列化しやすいため大規模化(スケーリング)にも向いていました。
鈴木:まさに理想的ですね。
ChatGPTにもトランスフォーマーが使われているのでしょうか?
外山:ChatGPTで使われている言語モデルはGPTといいますが、GPTは「Generative Pre-trained Transformers」の略ですよ。
鈴木:ChatGPTの「T」は、トランスフォーマーを意味していたのですね。
GPTでも、大量の文章を学習させ、それによって文章を予測することができるようになるという流れは同じなのですよね?
外山:実は、GPTは、文章全体を予測しているのではありません。ユーザーの入力を受けて、次に続く確率が最も高い単語(正確には「トークン」という単位です)を予測しているのです。
鈴木:例えば、以下のように、次の単語を予測し続けることで、文章を作成しているということですか?
日本 ⇒ で ⇒ 一番 ⇒ 高い ⇒ 山 ⇒ は ⇒ 富士山
外山:その通りですが、実際には、複数の単語が候補として挙がり、その中から最も確率の高いものが選ばれていくのです。
鈴木:ChatGPTは、一貫した長文を書くことができますし、人間の感情を理解しているかのような表現も書けます。「次に続く確率が高い単語を予測する」という仕組みだけで実現されているというのは、信じられないですね。
外山:これがトランスフォーマーの威力だということですね。
それに加えて、現在の言語モデルは非常に大規模になっているという点も大きいです。
機械学習のモデルの規模を表すためには、パラメーターの数が用いられることが多いです。具体的に比較をしてみましょう。前回、最小二乗法で一次方程式( y = ax + b )を扱いましたが、パラメーターはaとbの2個だけでした。
一番最初に例示したようなニューラルネットワークの場合、ニューロン同士をつなぐ各線と、各ニューロン(ただし、入力層にはパラメーターは設定されないのが通常)にパラメーターが1つずつ割りあてられるのが普通です。
3層構造の場合、隠れ層に4個、出力層に3個のニューロンと、入力層から隠れ層への3×4=12本の線、隠れ層から出力層への4×3=12本の線のそれぞれにパラメーターが割り当てられ、合計31個(4+3+12+12=31)となるわけです。
では、現在のChatGPTなどの最先端モデルのパラメーター数はいくつくらいか予想できますか?
鈴木:非常に大きな数だろうという予想はできますが、具体的には想像もつきませんね。
外山:大手AI企業の多くはパラメーター数を公表していませんが、1兆個を超えると言われています。
トランスフォーマーを用いても、パラメーター数が少ないうちは、あまり性能は高くありませんでした。徐々にパラメーターを増やし、巨大化していくうちに、現在のような高性能なAIになっていったわけです。トランスフォーマーは大規模化しやすい構造になっているため、今後さらに性能が向上していくことが期待できます。
●推論するAI
鈴木:最近の言語モデルは、数学にも強くなったと聞きます。文章を学習させただけで、数学の問題も解けるようになったということですか?
外山:数学に強くなったのは、推論能力が強化されたことが理由です。
2016年に、AIが囲碁のトップ棋士に勝ったというニュースがありました。あの囲碁AIには強化学習という技術が用いられていたのですが、現在の言語モデルには、その強化学習のノウハウが活かされており、論理的な推論をすることもできるのです。これにより、数学や論理問題、プログラミングなどの精度が大幅に向上しました。
鈴木:私たちが日常的に使うAIサービスのモデルも、推論を行っているのですか?
外山:ChatGPTでは「Thinking」、マイクロソフト社のCopilotなら「Think Deeper」、Geminiなら「思考モード」など、一目で推論モデルだと分かる名前が付いているので、選択してみてください。
推論することで回答の質が向上するので、うまく使えば業務の効率もアップすると思います。

外山 哲郎
有限責任パートナーズ綜合監査法人
金融系、ゲーム系、など幅広い分野でスマートフォンアプリやWebサイトの開発に携わる。 2017年からAI業務に従事。データ分析や、医療の分野でのAI活用の研究・開発などに携わる。 ライターとしても活動(ニコニコニュース(ニコニコ動画))。 2024年7月 有限責任パートナーズ綜合監査法人入所。 現在は、IT専門家として監査業務に携わる他、法人内のDXおよびAI活用を推進している。

鈴木 爽矢
有限責任パートナーズ綜合監査法人
2022年大学3年生時に公認会計士試験合格。 大学時代にはCPA会計学院で監査論のチューター及び広報部のマーケティング業務を行う。 その後大手監査法人、コンサルティング会社を経て現職の有限責任パートナーズ綜合監査法人に入所。 現在は主に、IPO準備会社や上場企業の会計監査に従事し、財務デューデリジェンスなどの非監査業務にも携わっている。